What if you could search for salaries not by exact keywords, but by describing a job in natural language? “Senior developer in Brussels with a company car” or “nurse working in Antwerp” — and get relevant results based on semantic similarity rather than string matching.
This is exactly what I built with BeSalary: an AI-powered salary search engine that extracts structured data from Reddit posts using local LLMs and enables semantic search through vector embeddings. You can try it live at besalary-wine.vercel.app.
In this post, I’ll walk through the entire pipeline: from automated data collection with GitHub Actions, to structured extraction with Ollama, to vector search with pgvector, and finally deployment on Vercel.
The Problem: Unstructured Salary Data
The Belgian subreddit r/besalary is a goldmine of salary information. Users post their compensation packages following a semi-structured template covering everything from gross/net salary to benefits like meal vouchers, company cars, and vacation days.
The challenge? While the posts follow a template, they’re still free-form text with variations, typos, and inconsistencies. I wanted to:
- Automatically collect new posts as they appear
- Extract structured data from unstructured text using AI
- Enable semantic search so users can find similar jobs by description
- Deploy a simple frontend to make it accessible
Part 1: Automated Data Collection with PRAW and GitHub Actions
The first step is collecting Reddit posts automatically. I used PRAW (Python Reddit API Wrapper) to fetch posts from r/besalary and store them in a PostgreSQL database hosted on Supabase.
The Reddit Scraper
import praw
import uuid
from datetime import datetime
from supabase import create_client, Client
# Initialize Reddit client
reddit = praw.Reddit(
client_id=os.environ.get("PRAW_CLIENT_ID"),
client_secret=os.environ.get("PRAW_CLIENT_SECRET"),
password=os.environ.get("PRAW_PASSWORD"),
user_agent=os.environ.get("PRAW_USER_AGENT", "besalary"),
username=os.environ.get("PRAW_USERNAME"),
)
# Fetch hot posts from the subreddit
posts = reddit.subreddit("besalary").hot(limit=1000)
# Transform and collect posts
list_of_items = []
for post in posts:
list_of_items.append({
"uuid": str(uuid.uuid5(uuid.NAMESPACE_URL, f"reddit_post:{post.id}")),
"title": post.title,
"selftext": post.selftext,
"created_utc": datetime.utcfromtimestamp(post.created_utc).isoformat(),
"permalink": post.permalink,
"reddit_id": post.id,
})
# Upsert to Supabase (handles duplicates via reddit_id)
supabase.table("reddit_post").upsert(
list_of_items,
on_conflict="reddit_id"
).execute()
The key insight here is using uuid5 with the Reddit post ID to generate deterministic UUIDs. This ensures idempotency — running the script multiple times won’t create duplicates.
Scheduling with GitHub Actions
To keep the data fresh, I set up a GitHub Actions workflow that runs daily:
on:
push:
branches:
- main
schedule:
- cron: '27 15 * * *' # Daily at 15:27 UTC
jobs:
build:
runs-on: ubuntu-latest
environment: secrets
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: install python packages
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: execute py script
env:
PRAW_CLIENT_ID: ${{ secrets.PRAW_CLIENT_ID }}
PRAW_CLIENT_SECRET: ${{ secrets.PRAW_CLIENT_SECRET }}
PRAW_PASSWORD: ${{ secrets.PRAW_PASSWORD }}
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
SUPABASE_SERVICE_ROLE_KEY: ${{ secrets.SUPABASE_SERVICE_ROLE_KEY }}
run: python besalary.py
This approach has several advantages:
- Zero infrastructure cost — GitHub Actions free tier is more than enough
- Automatic retries — GitHub handles failures gracefully
- Secret management — Credentials are stored securely in GitHub Secrets
- Audit trail — Every run is logged and visible in the Actions tab
The Data Quality Problem
Not every post on r/besalary contains actual salary data. Many posts are questions about salary negotiation, discussions about benefits, or off-topic content. Running LLM extraction on these wastes compute and pollutes the database with hallucinated data.
I needed a way to pre-filter posts before sending them to the extraction pipeline. The solution? A simple labeling tool with keyboard shortcuts for rapid annotation.
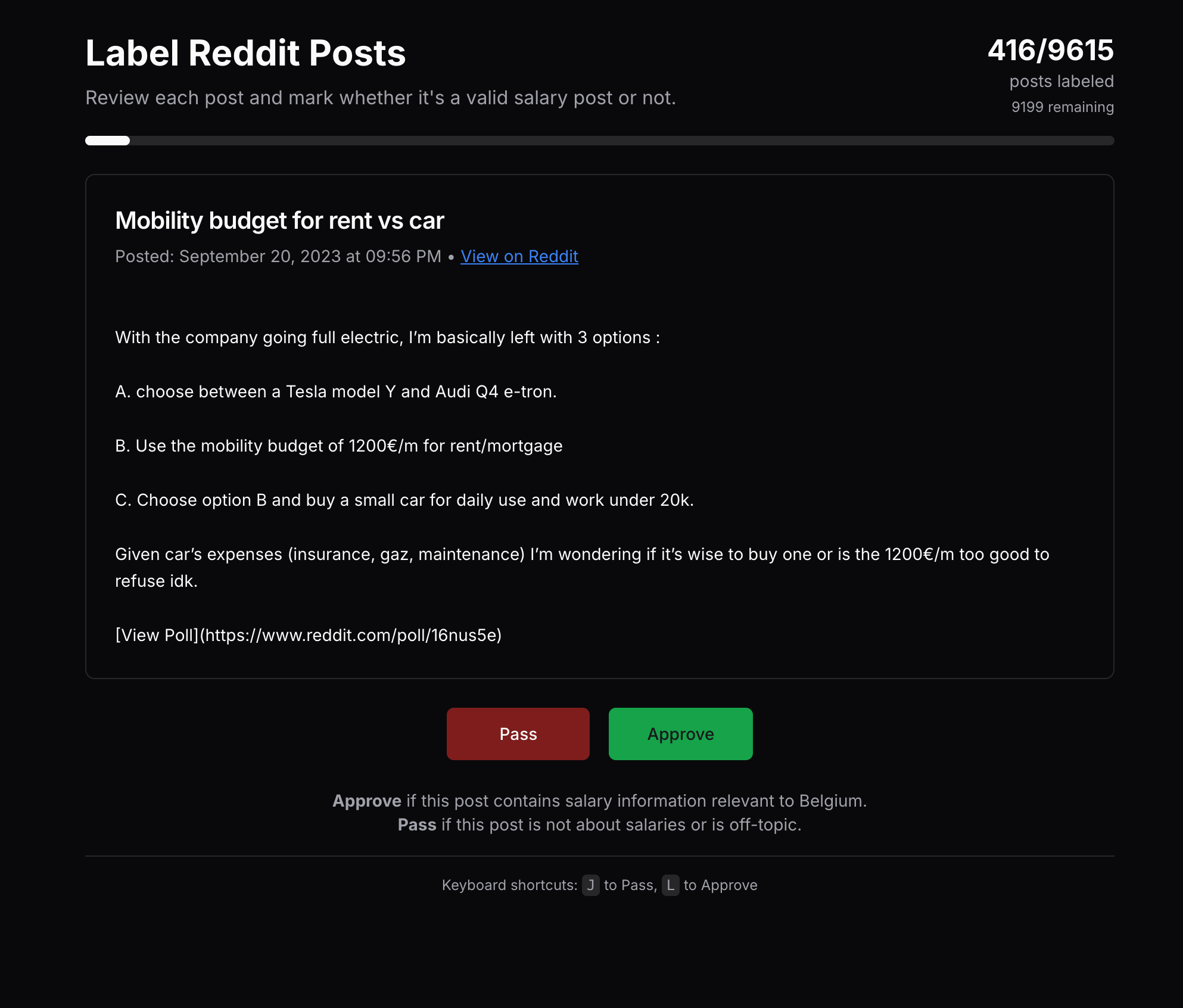
The tool displays each post with Pass (J) and Approve (L) buttons. A progress bar shows how many posts have been labeled out of the total (~9600 posts). This human-in-the-loop approach lets me quickly flag which posts actually contain salary information worth extracting.
The labeled data feeds back into the pipeline: only posts marked as valid (should_attempt = true) get sent to the LLM for extraction. This reduced wasted extraction attempts by roughly 40% and significantly improved data quality.
Part 2: Structured Extraction with Ollama and Pydantic
Now comes the interesting part: extracting structured salary data from free-form Reddit posts. I chose to use Ollama to run LLMs locally, specifically the llama3.2 model.
Why Local LLMs?
- Privacy — Salary data is sensitive; keeping it local avoids sending it to external APIs
- Cost — No per-token charges for processing hundreds of posts
- Control — Full control over the model and its behavior
- Speed — No network latency for inference
The Pydantic Schema
First, I defined a strict schema for the extracted data using Pydantic:
from pydantic import BaseModel
class BesalaryEntry(BaseModel):
post_id: str
age: int
education: str
work_experience: int
sector: str
amount_of_employees: int
multinational: bool
job_title: str
job_description: str
city_region_of_work: str
official_hours_week: int
vacation_days_year: int
gross_salary_month: int
net_salary_month: int
netto_compensation: int
salary_car: str
thirteenth_month: str
meal_vouchers: str
ecocheques: str
salary_car_bool: bool
thirteenth_month_bool: bool
meal_vouchers_bool: bool
ecocheques_bool: bool
This schema serves multiple purposes:
- Validation — Ensures extracted data matches expected types
- Documentation — Self-documenting structure
- LLM guidance — The JSON schema is passed to Ollama for structured output
The Extraction Pipeline
The extraction script processes posts in batches, using Ollama’s structured output feature:
from ollama import chat
from pydantic_model import BesalaryEntry
def process_post(row):
salary_query = f"""
Extract salary and job information from this Belgian salary post.
Post Title: {row['title']}
Post Content: {row['selftext']}
Please extract the following information if available:
- Personal info: age, education, work experience
- Job details: title, description, sector/industry, seniority
- Company: number of employees, multinational status
- Salary: gross monthly, net monthly, 13th month details
- Benefits: meal vouchers, ecocheques, car/mobility
- Work conditions: official hours per week, vacation days
- Location: city/region of work
Be sure to look for information in sections like:
- PERSONALIA (for age, education)
- EMPLOYER PROFILE (for sector, employees, multinational)
- CONTRACT & CONDITIONS (for job title, hours, vacation)
- SALARY (for all salary and benefit details)
- MOBILITY (for city/region and commute)
"""
response = chat(
messages=[
{
'role': 'system',
'content': 'You are an expert at extracting structured salary '
'information from Belgian salary posts.'
},
{
'role': 'user',
'content': salary_query
}
],
model="llama3.2",
format=BesalaryEntry.model_json_schema(), # Structured output!
)
# Validate and parse the response
extracted_data = BesalaryEntry.model_validate_json(response.message.content)
return extracted_data
The magic here is format=BesalaryEntry.model_json_schema(). This tells Ollama to constrain its output to match the Pydantic schema exactly, eliminating parsing errors and ensuring type safety.
Quality Control
Not every extraction is successful. I implemented validation to only save entries that have the essential fields:
if (extracted_data.gross_salary_month and
extracted_data.net_salary_month and
extracted_data.job_title is not None):
save_besalary_entry(extracted_data)
mark_post_extracted(row['reddit_id'])
This ensures the database only contains usable entries with actual salary information.
Part 3: Vector Embeddings and Semantic Search
With structured data in place, the next step is enabling semantic search. Instead of keyword matching, I wanted users to describe a job and find similar entries based on meaning.
Generating Embeddings
I used the nomic-embed-text model through Ollama to generate 768-dimensional embeddings for each salary entry. The embeddings are created from a combination of job title and description, then stored in PostgreSQL using the pgvector extension.
The Search API
The search endpoint generates an embedding for the user’s query and finds the most similar entries using cosine distance:
import prisma from '@/lib/prisma';
import { NextRequest, NextResponse } from 'next/server';
export async function GET(req: NextRequest) {
const params = req.nextUrl.searchParams.get("params") ?? '';
// Generate embedding for the search query using Nomic API
const response = await fetch('https://api-atlas.nomic.ai/v1/embedding/text', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + process.env.NOMIC_API_KEY
},
body: JSON.stringify({
texts: [params],
task_type: 'search_document',
max_tokens_per_text: 8192,
dimensionality: 768
})
});
const data = await response.json();
const nomicEmbedding = JSON.stringify(data.embeddings[0]);
// Find the 20 most similar entries using cosine similarity
const entries = await prisma.$queryRaw<BesalaryEntry[]>`
SELECT e.*
FROM embeddings em
JOIN "BesalaryEntry" e ON em.entry_uuid = e.uuid
WHERE e.gross_salary_month IS NOT NULL
AND e.net_salary_month IS NOT NULL
AND e.job_title IS NOT NULL
AND e.job_title != ''
ORDER BY em.nomic <-> ${nomicEmbedding}::vector
LIMIT 20;
`;
return NextResponse.json(entries);
}
The <-> operator is pgvector’s cosine distance operator. Lower values mean more similar vectors, so we order ascending and limit to 20 results.
Part 4: Deployment
The frontend is a Next.js application deployed on Vercel with automatic deployments from the main branch. The database connection uses Prisma with connection pooling optimized for serverless environments.
Database Schema
The Prisma schema ties everything together:
model reddit_post {
uuid String @id @default(cuid())
created_utc DateTime @db.Timestamptz(6)
title String?
selftext String?
permalink String?
reddit_id String @unique
is_extracted Boolean @default(false)
is_attempted Boolean @default(false)
BesalaryEntry BesalaryEntry[]
}
model BesalaryEntry {
uuid String @id @default(cuid())
age Int?
education String?
job_title String?
gross_salary_month Int?
net_salary_month Int?
// ... other fields
post reddit_post? @relation(fields: [post_id], references: [reddit_id])
BesalaryEntryEmbeddings Embeddings[]
}
model Embeddings {
uuid String @id @default(cuid())
entryUuid String @map("entry_uuid")
nomic Unsupported("vector")?
entry BesalaryEntry @relation(fields: [entryUuid], references: [uuid])
}
Lessons Learned
What Worked Well
- Structured LLM output — Using Pydantic schemas with Ollama’s format parameter eliminated parsing headaches
- Local LLMs — Running Ollama locally was surprisingly fast and cost-effective
- pgvector — Vector search directly in PostgreSQL simplified the architecture significantly
- GitHub Actions — Perfect for scheduled data collection with zero infrastructure overhead
Challenges
- Data quality — Not all Reddit posts follow the template perfectly; some extraction failures are inevitable
- LLM hallucinations — Occasionally the model invents data that isn’t in the post; validation helps but isn’t perfect
- Embedding consistency — Using the same embedding model for indexing and querying is crucial
Future Improvements
- RAG for better extraction — Use the original post as context when displaying results
- Analytics dashboard — Visualize salary trends by sector, region, and experience
- Fine-tuning — Train a specialized model on Belgian salary data for better extraction accuracy
- Real-time updates — Stream new posts instead of daily batches
Conclusion
This project demonstrates a complete AI pipeline: from data collection to LLM-powered extraction to vector search to deployment. The key technologies — PRAW, Ollama, pgvector, Next.js, and Vercel — work together seamlessly to create a useful application.
The combination of local LLMs for privacy-sensitive data processing and vector embeddings for semantic search is a powerful pattern that applies to many domains beyond salary data.
Try it yourself: besalary-wine.vercel.app
If you’re working on similar projects or have questions about the implementation, feel free to reach out on LinkedIn or GitHub.